Introduction
In this post, the San Francisco Rentals data set is used to demonstrate data reshaping in R. This involves changing the number of columns and rows in a data frame to fit a given use case. A data frame is made more tall or narrow by decreasing the number of columns, and wider by increasing the number of columns. The three reshaping methods covered in this article are:
- Making a data frame more narrow by summarising variables using group_by() and tally()
- Making a data frame wider with pivot_wider()
- “Lengthening” a data frame with pivot_longer()
Data frames created with these methods were used to make two plots:
- Count of construction permits by type per street
- Annual construction by type per San Francisco county
Setup
Loading the R libraries and data set.
# Loading libraries
library(tidytuesdayR)
library(tidyverse)
library(tidytext)
library(ggthemes)
# Loading data
tt <- tt_load("2022-07-05")
Downloading file 1 of 3: `rent.csv`
Downloading file 2 of 3: `sf_permits.csv`
Downloading file 3 of 3: `new_construction.csv`Reshaping a data frame by summarising variables
# Printing a summary of the San Francisco (SF) permits data frame
tt$sf_permits# A tibble: 86,103 × 44
permit_number permit_type permit_type_definiti… permit_creation_da…
<dbl> <dbl> <chr> <dttm>
1 2000010368 3 additions alteration… 2000-01-03 00:00:00
2 2000010353 6 demolitions 2000-01-03 00:00:00
3 2000010498 3 additions alteration… 2000-01-04 00:00:00
4 2000010484 3 additions alteration… 2000-01-04 00:00:00
5 2000010480 3 additions alteration… 2000-01-04 00:00:00
6 2000010475 3 additions alteration… 2000-01-04 00:00:00
7 2000010476 3 additions alteration… 2000-01-04 00:00:00
8 2000010474 3 additions alteration… 2000-01-04 00:00:00
9 2000010479 3 additions alteration… 2000-01-04 00:00:00
10 20000104173 3 additions alteration… 2000-01-04 00:00:00
# … with 86,093 more rows, and 40 more variables: block <chr>,
# lot <chr>, street_number <dbl>, street_number_suffix <chr>,
# street_name <chr>, street_suffix <chr>, unit <dbl>,
# unit_suffix <chr>, description <chr>, status <chr>,
# status_date <dttm>, filed_date <dttm>, issued_date <dttm>,
# completed_date <dttm>, first_construction_document_date <dttm>,
# structural_notification <chr>, …# Printing a summary of the shape of the data frame
paste("tt$sf_permits has", nrow(tt$sf_permits), "rows and", ncol(tt$sf_permits),
"columns.")[1] "tt$sf_permits has 86103 rows and 44 columns."# Creating a tall/narrow data set of permits per street
permits_per_street <- tt$sf_permits %>%
# Selecting variables/columns to keep
select(permit_type_definition, street_name, permit_number) %>%
# Grouping the permit numbers by type and street name for counting
group_by(permit_type_definition, street_name) %>%
# Counting/tallying the number of permits by type per street
tally()
# Printing a summary of the permits per street data frame
permits_per_street# A tibble: 3,053 × 3
# Groups: permit_type_definition [4]
permit_type_definition street_name n
<chr> <chr> <int>
1 additions alterations or repairs 01st 196
2 additions alterations or repairs 02nd 763
3 additions alterations or repairs 03rd 778
4 additions alterations or repairs 04th 338
5 additions alterations or repairs 05th 223
6 additions alterations or repairs 06th 347
7 additions alterations or repairs 07th 199
8 additions alterations or repairs 08th 252
9 additions alterations or repairs 08th Ti 1
10 additions alterations or repairs 09th 301
# … with 3,043 more rows# Printing a summary of the shape of the data frame
paste("permits_per_street has", nrow(permits_per_street), "rows and",
ncol(permits_per_street), "columns.")[1] "permits_per_street has 3053 rows and 3 columns."Reshaping a data frame to make it wider with the {tidyr} function pivot wider
# Creating a wider copy of the permits per street data frame
permits_per_street_wider <- permits_per_street %>%
# Pivoting the street names wider (creating a column for each street) and
# selecting the "n" variable for the values in this data frame
pivot_wider(names_from = street_name, values_from = n)
# Printing the wider permits per street data frame
permits_per_street_wider# A tibble: 4 × 1,588
# Groups: permit_type_definition [4]
permit_type_defini… `01st` `02nd` `03rd` `04th` `05th` `06th` `07th`
<chr> <int> <int> <int> <int> <int> <int> <int>
1 additions alterati… 196 763 778 338 223 347 199
2 demolitions 16 17 72 8 7 17 24
3 new construction 9 9 26 8 3 4 13
4 new construction w… NA 3 48 3 4 8 7
# … with 1,580 more variables: `08th` <int>, `08th Ti` <int>,
# `09th` <int>, `10th` <int>, `11th` <int>, `12th` <int>,
# `13th` <int>, `13th Ti` <int>, `14th` <int>, `15th` <int>,
# `16th` <int>, `17th` <int>, `18th` <int>, `19th` <int>,
# `20th` <int>, `21st` <int>, `22nd` <int>, `23rd` <int>,
# `24th` <int>, `25th` <int>, `25th North` <int>, `26th` <int>,
# `27th` <int>, `28th` <int>, `29th` <int>, `2nd` <int>, …# Printing a summary of the shape of the data frame
paste("permits_per_street_wider has", nrow(permits_per_street_wider), "rows and",
ncol(permits_per_street_wider), "columns.")[1] "permits_per_street_wider has 4 rows and 1588 columns."Reshaping a data frame to make it more narrow with the {tidyr} function pivot longer
# Printing a summary of the new construction data frame
tt$new_construction# A tibble: 261 × 10
cartodb_id the_geom the_geom_webmerca… county year totalproduction
<dbl> <lgl> <lgl> <chr> <dbl> <dbl>
1 1 NA NA Alame… 1990 3601
2 2 NA NA Alame… 1991 226
3 3 NA NA Alame… 1992 2652
4 4 NA NA Alame… 1993 3049
5 5 NA NA Alame… 1994 2617
6 6 NA NA Alame… 1995 3515
7 7 NA NA Alame… 1996 3179
8 8 NA NA Alame… 1997 4591
9 9 NA NA Alame… 1998 6022
10 10 NA NA Alame… 1999 5601
# … with 251 more rows, and 4 more variables: sfproduction <dbl>,
# mfproduction <dbl>, mhproduction <dbl>, source <chr># Printing a summary of the shape of the data frame
paste("tt$new_construction has", nrow(tt$new_construction), "rows and",
ncol(tt$new_construction), "columns.")[1] "tt$new_construction has 261 rows and 10 columns."# Creating a taller/more narrow subset of production type per county
production_per_county <- tt$new_construction %>%
# Selecting variables/columns from tt$new_construction
select(county, year, totalproduction, sfproduction, mfproduction,mhproduction) %>%
# "Lengthening" the data frame by selecting columns to be pivoted to a longer format
pivot_longer(cols = c(totalproduction, sfproduction, mfproduction, mhproduction)) %>%
# Creating a copy of the "name" column to the more descriptive "production_type", as the
# pivoted columns all describe types of production, and removing the original "name"
# column
mutate(production_type = name, name = NULL) %>%
# Changing "production_type" from a character to a factor variable, with more
# descriptive factor levels
mutate(production_type = fct_recode(production_type,
"Total" = "totalproduction", "Single family" = "sfproduction",
"Multi family" = "mfproduction", "Mobile home" = "mhproduction"))
# Printing a summary of the production per county data frame
production_per_county# A tibble: 1,044 × 4
county year value production_type
<chr> <dbl> <dbl> <fct>
1 Alameda County 1990 3601 Total
2 Alameda County 1990 2166 Single family
3 Alameda County 1990 1378 Multi family
4 Alameda County 1990 57 Mobile home
5 Alameda County 1991 226 Total
6 Alameda County 1991 -236 Single family
7 Alameda County 1991 395 Multi family
8 Alameda County 1991 67 Mobile home
9 Alameda County 1992 2652 Total
10 Alameda County 1992 2018 Single family
# … with 1,034 more rows# Printing a summary of the shape of the data frame
paste("production_per_county has", nrow(production_per_county), "rows and",
ncol(production_per_county), "columns.")[1] "production_per_county has 1044 rows and 4 columns."Plotting permit type counts per street using a tidy data frame of value counts
# Plotting the top 20 streets with the total number of each permit category
permits_per_street %>%
slice_max(order_by = n, n = 20) %>%
mutate(street_name = reorder_within(street_name, n, permit_type_definition)) %>%
ggplot(aes(x = n, y = street_name, fill = permit_type_definition)) +
geom_col(show.legend = FALSE) +
scale_y_reordered() +
theme_solarized_2() +
facet_wrap(~permit_type_definition, ncol = 2, scales = "free") +
labs(title = "Count of construction permits by type per street",
x = "Tally", y = "Street name")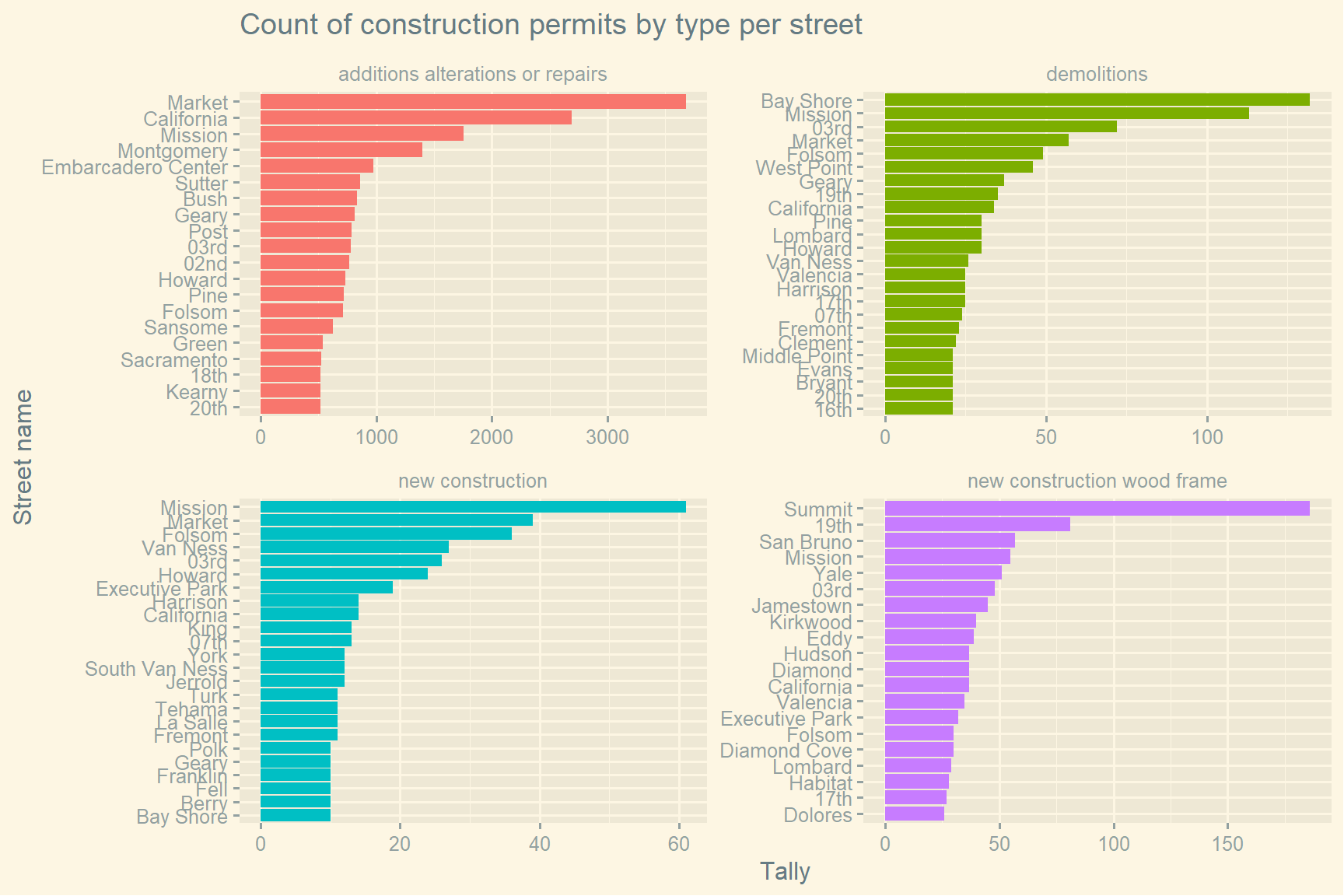
Plotting annual construction per San Francisco county using a data frame created with pivot longer
# Plotting the annual construction by type per San Francisco county
production_per_county %>%
ggplot(aes(x = year, y = value,
colour = fct_reorder2(production_type, year, value))) +
geom_line() +
theme_clean() +
facet_wrap(~county, scales = "free") +
scale_colour_brewer(palette = "Dark2") +
scale_x_continuous(breaks =
seq(min(production_per_county$year), max(production_per_county$year), 8)) +
geom_vline(xintercept = 2008, linetype = 2, colour = "red", size = 0.4) +
labs(colour = "Production type", x = "Year", y = "Units",
title = "Annual construction by type per San Francisco county",
subtitle = "Red vertical line marks 2008")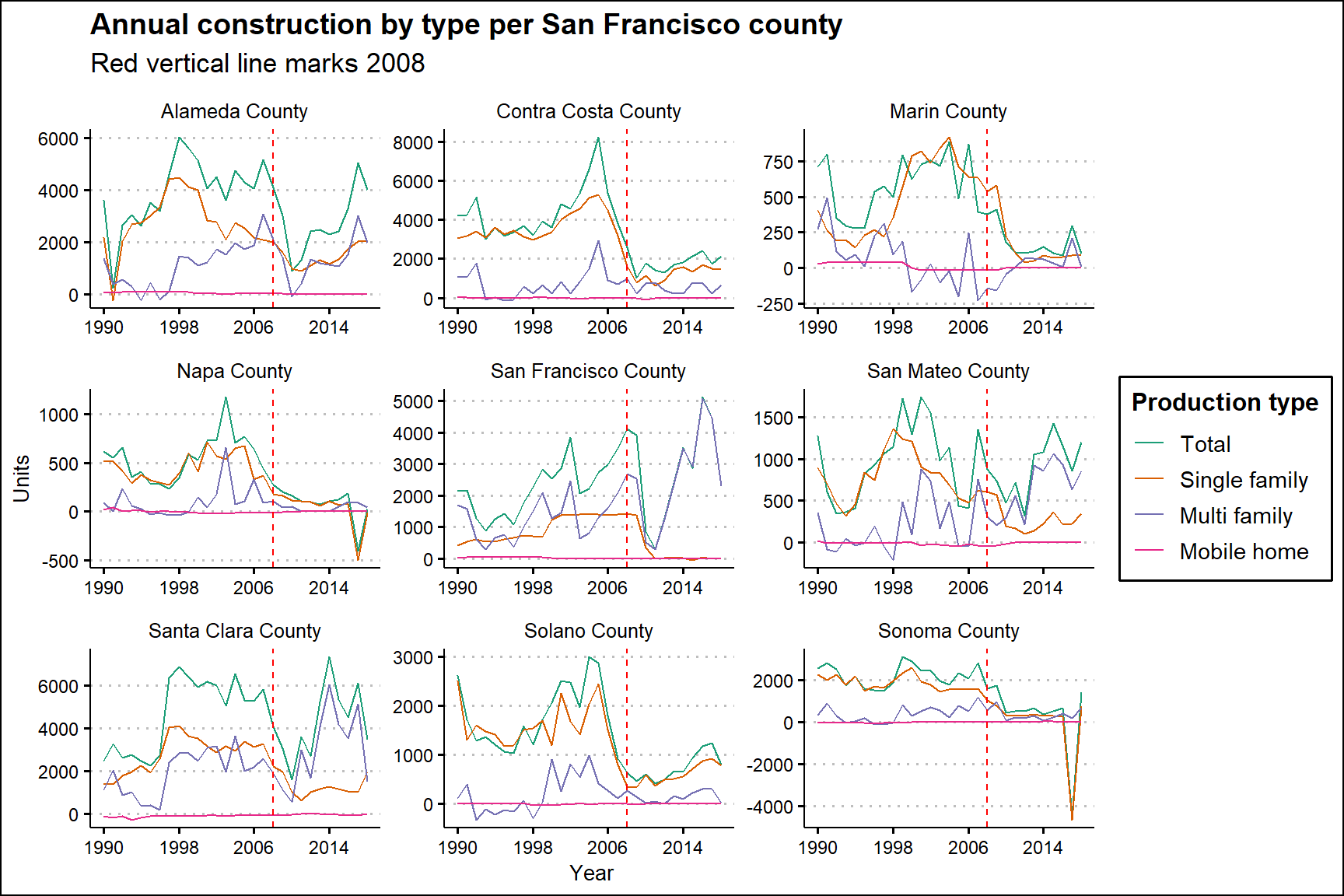
Figure 1: In San Francisco county, new construction plateaued in 2008 before plummeting.